A observabilidade de middleware amplia a visibilidade sobre o comportamento das aplicações, permitindo detecção proativa de incidentes, otimização de performance e maior confiabilidade dos sistemas corporativos.
À medida que as aplicações empresariais evoluem para arquiteturas distribuídas e altamente dinâmicas, o middleware continua sendo a camada crítica que conecta serviços, bancos de dados e sistemas externos. No entanto, abordagens tradicionais de monitoramento já não dão conta da complexidade desses ambientes.
A observabilidade surge como uma capacidade fundamental que vai além do monitoramento básico, oferecendo visibilidade profunda do comportamento dos sistemas por meio de logs, métricas e traces. Com ela, é possível antecipar problemas, otimizar desempenho e sustentar a resiliência das operações.
Neste artigo, a Safelevel apresenta o conceito de observabilidade aplicada ao middleware, sua importância no ecossistema corporativo moderno e estratégias práticas para implementação.
Do monitoramento tradicional à observabilidade
O monitoramento tradicional foca em métricas e alertas predefinidos — uso de CPU, consumo de memória, disponibilidade. É útil, mas frequentemente falha diante de problemas inesperados ou comportamentos sistêmicos complexos.
A observabilidade permite que as equipes compreendam por que um sistema se comporta de determinada forma, analisando três pilares:
- Logs – registros de eventos do sistema
- Métricas – indicadores quantitativos de performance
- Traces – rastreamento do fluxo de requisições entre serviços
Em ambientes de middleware, esses pilares fornecem visibilidade ponta a ponta das interações entre aplicações, acelerando diagnósticos e aumentando a precisão das análises.
Por que a observabilidade de middleware é essencial
O middleware sustenta funções estratégicas em sistemas corporativos, como:
- Comunicação entre aplicações
- Processamento de transações
- Workflows de integração
- Gerenciamento de recursos
Sem observabilidade adequada, as organizações enfrentam:
- Detecção tardia de incidentes
- Análise de causa-raiz limitada
- Gargalos de performance
- Maior risco de indisponibilidade
Implementar observabilidade garante que o middleware permaneça confiável, eficiente e escalável diante de cargas de trabalho variáveis.
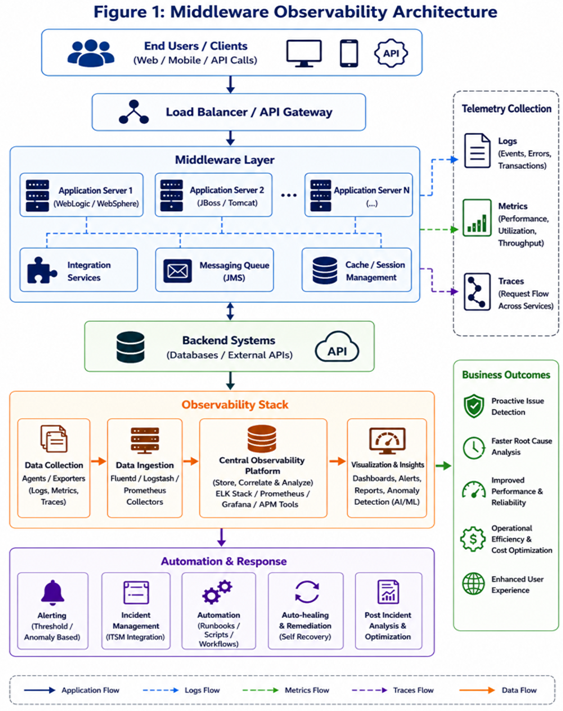
Componentes centrais de uma estratégia de observabilidade
Agregação e análise de logs
Logs capturam eventos e erros detalhados. A centralização desses registros permite identificar anomalias, depurar falhas e acompanhar o comportamento do sistema ao longo do tempo.
Coleta de métricas
As métricas oferecem visibilidade quantitativa sobre o desempenho — tempo de resposta, throughput, taxa de erros — e ajudam a detectar degradações precocemente.
Distributed tracing
O rastreamento distribuído acompanha cada requisição enquanto ela atravessa múltiplos serviços. É fundamental em arquiteturas de microsserviços, onde uma única transação pode envolver dezenas de componentes.
Dashboards e visualização
Painéis consolidam os dados de observabilidade em uma visão unificada, possibilitando monitoramento em tempo real e tomada de decisão mais ágil.
Principais desafios na adoção
- Lidar com grandes volumes de logs e métricas
- Correlacionar dados entre múltiplos sistemas
- Instrumentar aplicações legadas
- Controlar o overhead das ferramentas de monitoramento
- Garantir segurança e conformidade dos dados coletados
Superar esses obstáculos exige uma estratégia bem estruturada, com escolha adequada de ferramentas e governança de dados.
Como implementar observabilidade em ambientes de middleware
1. Instrumentação
Aplicações e componentes de middleware devem ser instrumentados para emitir logs, métricas e traces — seja por agentes, SDKs ou frameworks nativos.
2. Coleta centralizada
Todos os dados de telemetria devem convergir para uma plataforma central, viabilizando correlação e análise unificada.
3. Correlação dos dados de telemetria
Conectar logs, métricas e traces fornece a visão completa do comportamento do sistema, acelerando a análise de causa-raiz.
4. Monitoramento e alertas em tempo real
Mecanismos avançados de alerta detectam anomalias e disparam respostas proativas antes que incidentes escalem para o usuário final.
5. Otimização contínua
Observabilidade não é projeto pontual: requer ajustes frequentes para acompanhar a evolução das cargas de trabalho e da arquitetura.
O papel da observabilidade na arquitetura moderna
Com a expansão de microsserviços, contêineres e ambientes de nuvem híbrida, o middleware tornou-se mais distribuído e complexo. A observabilidade é fundamental para:
- Gerenciar dependências entre serviços
- Sustentar a performance das aplicações
- Apoiar práticas de DevOps e SRE
- Acelerar a resolução de incidentes
Além disso, ela aproxima times de desenvolvimento e operações, criando uma base comum de visibilidade sobre o sistema.
Impactos para o negócio
- Redução de downtime por meio de detecção proativa
- Análise de causa-raiz mais rápida
- Melhoria de performance e experiência do usuário
- Maior eficiência operacional
- Decisões orientadas por dados
Como consequência, as organizações reduzem custos operacionais ao diminuir esforço manual de troubleshooting e aumentar a confiabilidade dos serviços.
Tendências futuras
- Detecção de anomalias baseada em IA
- Analytics preditivo para prevenção de falhas
- Análise automatizada de causa-raiz
- Integração com automação e sistemas auto-recuperáveis (self-healing)
Conclusão
A observabilidade de middleware deixou de ser opcional. Em ambientes cada vez mais complexos, sustentar confiabilidade, performance e escalabilidade depende da adoção de práticas avançadas de observabilidade — combinando instrumentação abrangente, análise centralizada, alertas em tempo real e melhoria contínua.
Na Safelevel, acreditamos que investir em observabilidade é transformar a capacidade operacional do negócio, reduzir riscos e construir ecossistemas de aplicações verdadeiramente resilientes.